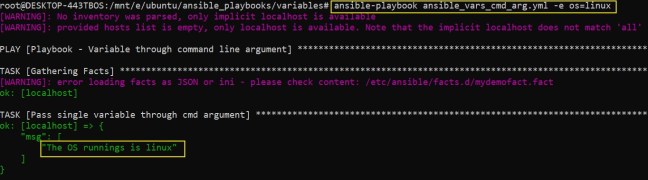
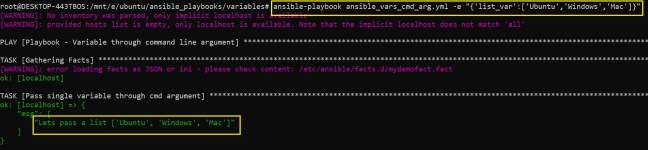
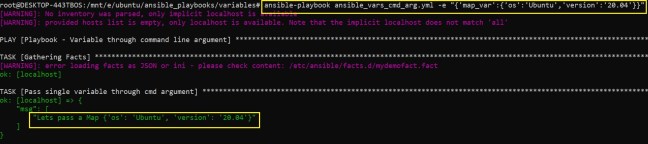
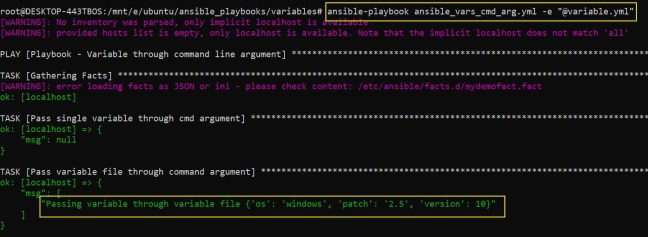
As a DevOps engineer, we do encounter such cryptic error messages while launching infrastructures. In the below post, we will try to understand one such error while creating an Auto Scaling Group in AWS cloud, with a possible workaround.
Error:
Error: creating Auto Scaling Group : ValidationError: You must use a valid fully-formed launch template. Value () for parameter groupId is invalid. The value cannot be empty
│ status code: 400, request id: aac314dd-082f-4634-82ca-8bd6
Backgroud
We are trying to create an Auto Scaling group with a launch template.
# Auto Scale Group
resource "aws_autoscaling_group" "osc_asg_application" {
name = "osc-asg-application"
max_size = 1
min_size = 1
desired_capacity = 1
vpc_zone_identifier = [aws_subnet.osc_application.id]
launch_template {
id = aws_launch_template.osc_application_launch_template.id
version = "$Latest"
}
tag {
key = "name"
value = "osc-asg-application"
propagate_at_launch = true
}
}# Launch Template
resource "aws_launch_template" "osc_application_launch_template" {
name = "osc-application-launch-template"
image_id = data.aws_ami.cloudfront_ami.image_id
key_name = "demokey"
instance_type = "t2.micro"
security_group_names = [aws_security_group.osc_security_group.id]
block_device_mappings {
device_name = "/dev/sdf"
ebs {
volume_size = 8
volume_type = "gp3"
}
}
dynamic "tag_specifications" {
for_each = var.tag_resource
content {
resource_type = tag_specifications.value
tags = {
Name = "osc-application-resource"
}
}
}
tags = {
Name = "osc-application-launch-template"
}
}When we planned and applied the above terraform code, it failed with the following error code.

Error: creating Auto Scaling Group : ValidationError: You must use a valid fully-formed launch template. Value () for parameter groupId is invalid. The value cannot be empty
│ status code: 400, request id: aac314dd-082f-4634-82ca-8bd6b9fe69a6
Upon investigating the issue futher, we found the security group argument passed in launch template was wrong. We had passed the argument security_group_names instead of vpc_security_group_ids.
We made the changes in the launch template and updated the security group argument.
The updated working launch template code is as below,
resource "aws_launch_template" "osc_application_launch_template" {
name = "osc-application-launch-template"
image_id = data.aws_ami.cloudfront_ami.image_id
key_name = "demokey"
instance_type = "t2.micro"
vpc_security_group_ids = [aws_security_group.osc_security_group.id]
block_device_mappings {
device_name = "/dev/sdf"
ebs {
volume_size = 8
volume_type = "gp3"
}
}
dynamic "tag_specifications" {
for_each = var.tag_resource
content {
resource_type = tag_specifications.value
tags = {
Name = "osc-application-resource"
}
}
}
tags = {
Name = "osc-application-launch-template"
}
}